Markdown解析与编译(一)
Markdown 解析与编译(一)
前言
本篇主要讲我们的网站为什么要选择使用 mdx 去解析编译 markdown 文件,
而不是使用 react-markdown 去解析编译 markdown 文件,
我们选择使用 mdx 的原因不是因为 mdx 可以解析编译 md 文件中的 jsx 代码或可以导入组件,
而是 mdx 不仅支持实时编译还支持预编译,下面我们就来详细说说 mdx 支持的这两种编译方式。
实时编译
实时编译指的就是在浏览器中将 Markdown 编译为 React Node,实时编译的典型代表就是 react-markdown,
它就是在运行时对 Markdown 进行 Parse 与 Render,这样不好的地方就是会导致 bundle 体积变大,
同时也给浏览器造成了一定的性能压力,好处就是可以实时编译,我举几个例子大家就应该明白实时编译的用处了,例如实时代码编辑器
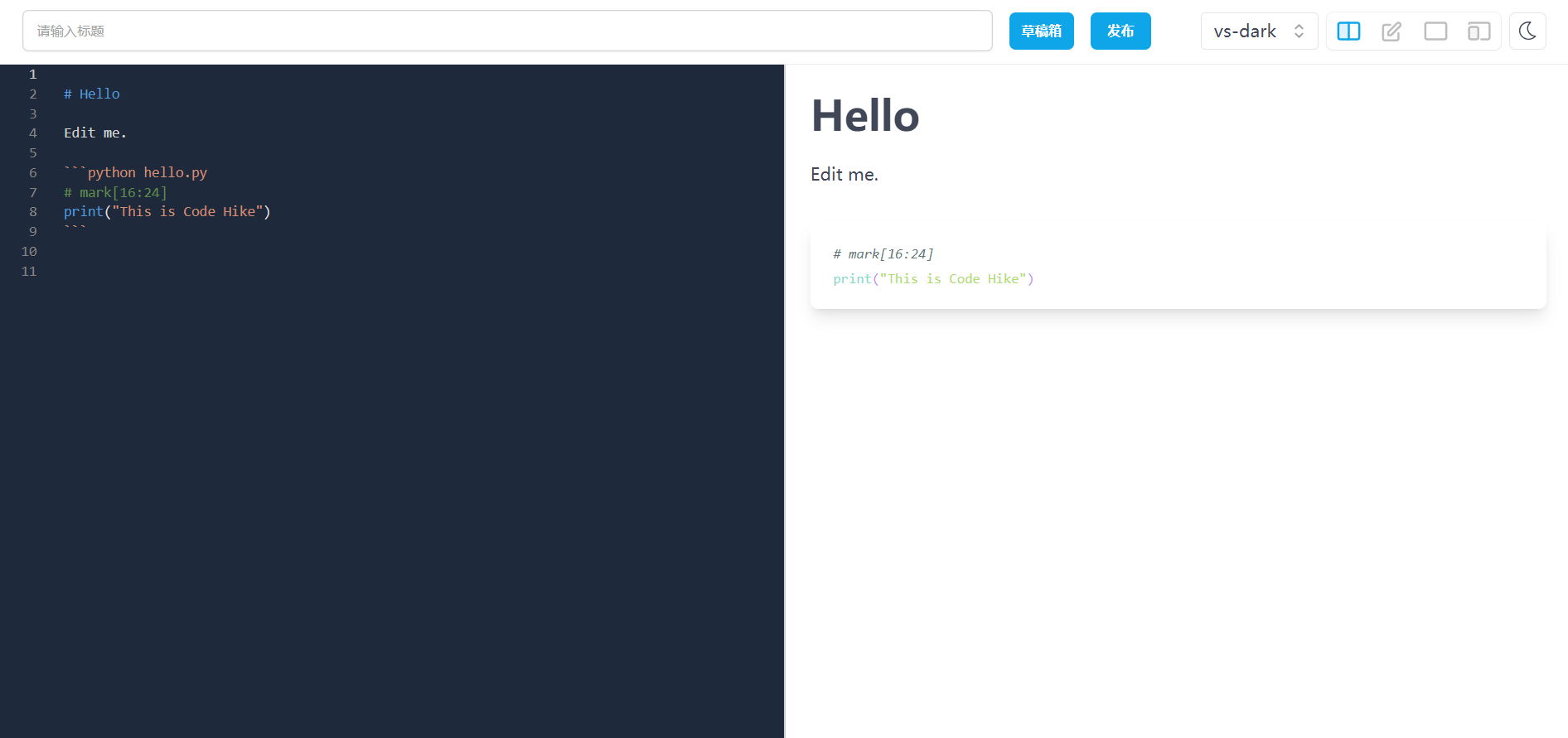
再举个例子就是最近很火的 chatGPT,如果 chatGPT 返回的内容包含代码,那代码部分就是用的实时编译去处理展示的
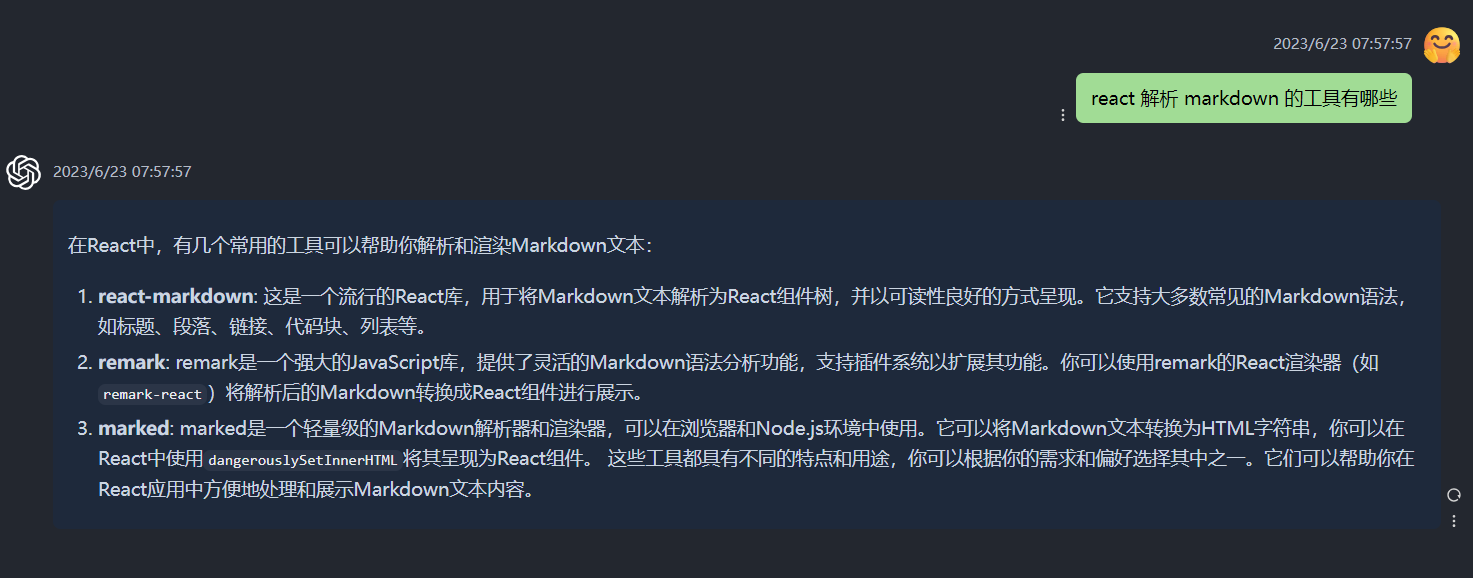
当然 mdx 也是支持实时编译的,我们的官网其实既用到了 mdx 的预编译也用到了 mdx 的实时编译,
下一个章节我会具体讲 mdx 实时编译与预编译的用法。
那为了改善客户端的性能,我们会想能不能将 Parse Markdown 的环节交给服务端处理,让浏览器运行时只负责 Render,那这就是预编译。
MDX 就是这种思路的一个实现,下面我们就来看看 mdx 的预编译。
预编译
上面我们说为了降低客户端浏览器的压力,可以让浏览器运行时只负责 Render,而服务端负责 Parse,
即在服务端预生成 HTML AST,在客户端将 HTML AST 渲染为 React 节点,这种在服务端就开始编译的方式我们就称为预编译。
下面通过例子具体来讲 mdx 的预编译。例如我们有如下 md 文档文件要在浏览器中展示。
假如你有好多这样的 md 文件或者 md 文件的内容很多,那就可以使用 mdx 的预编译大大降低客户端的压力,提高网站性能,给用户更好的体验。
具体在 Next.js 中就是在 build 时将 md 文件通过 mdx 编译器进行预编译、序列化后,将编译结果喂给 Next.js 的 getStaticProps 从而实现了 SSG。
在下一个章节我会具体讲如何使用 mdx 的实时编译与预编译功能。

