负载均衡机制
负载均衡的作用是将网络流量、数据请求或任务分配到多个服务器上,以达到资源优化利用、提高系统性能和可靠性的目的。
我们通过将负载均衡器放置在服务器集群前面,可以实现以下效果:
- 提高性能:负载均衡可以将网络流量或请求分散到多台服务器上,避免单一服务器过度负载而导致性能下降。
它可以根据服务器的负载情况智能地分配流量,确保每台服务器的负载保持在合理范围内,从而提高整体系统的响应速度和吞吐量。
- 提供可扩展性:当网站或应用程序的流量增加时,通过添加更多的服务器并使用负载均衡器进行分配,可以实现系统的水平扩展。
负载均衡器可以根据需要增加或减少所连接的服务器数量,灵活地应对流量峰值和变化,从而提供更好的可扩展性和弹性。
总之,负载均衡在分布式系统中起到了关键作用,通过合理地分配负载,提高了系统的性能、可靠性和可扩展性。
对于负载均衡机制,我们不仅提供了一致性哈希算法实现而且还提供了随机权重实现,默认使用一致性哈希算法。
一致性哈希
在分布式调度时,如何将任务均匀的分散到各个节点中,通常最容易想到的方案就是 hash 取模了。
可以将传入的 Key 按照 index = hash(key) % N 这样来计算出需要调度的节点。其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
这样可以满足任务的均匀分配,这似乎已经满足了我们目前的需求,但是当某天我们需要增加或删除了一个节点时,所有的 Key 都需要重新计算,显然这样成本较高。
为此需要一个算法满足分布均匀同时也要有良好的容错性和拓展性。
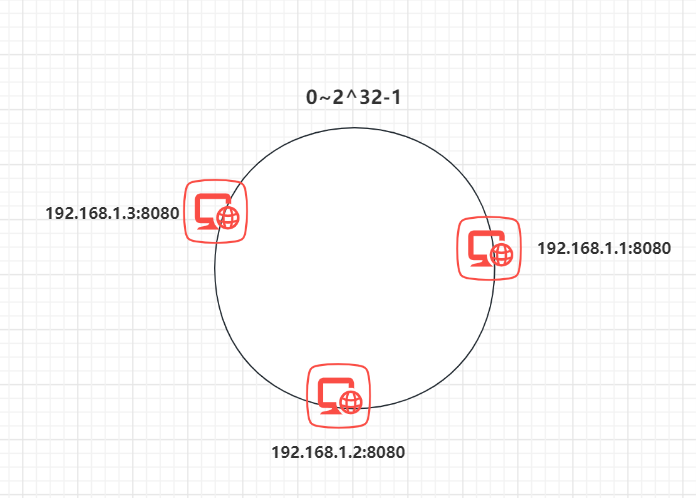
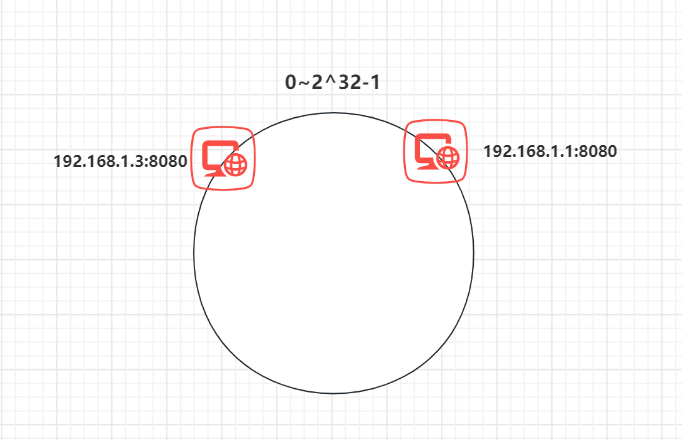
因此我们采用一致 Hash 算法,一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 0 ~ 2^32-1,这样就不用做取模操作了。如下图:

之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 hash(key),散列之后如下:
之后需要将任务定位到对应的节点上,使用同样的 hash 函数 将 Key 也映射到这个环上。
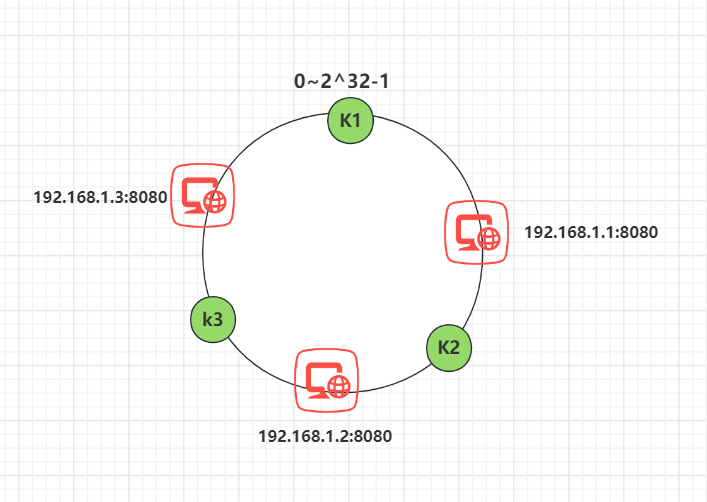
这样按照顺时针方向就可以把 k1 定位到 N1节点,k2 定位到 N3节点,k3 定位到 N2节点。
容错性
这时假设 N1 宕机了:
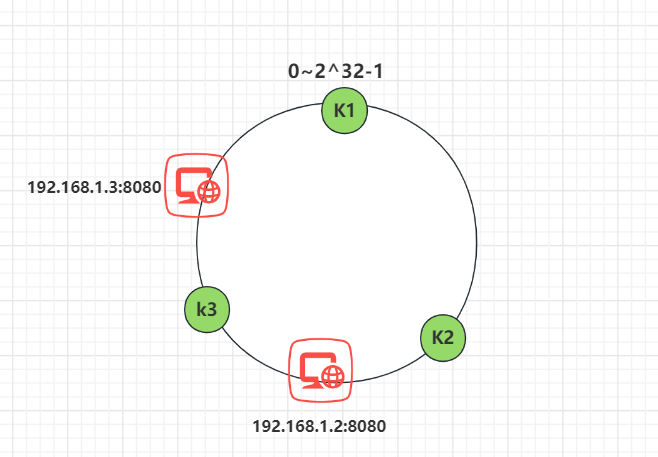
依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
拓展性
当新增一个节点时:
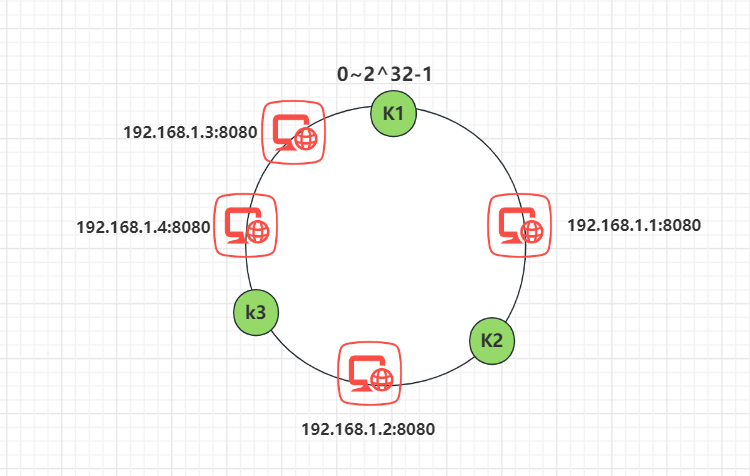
在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受影响的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
虚拟节点
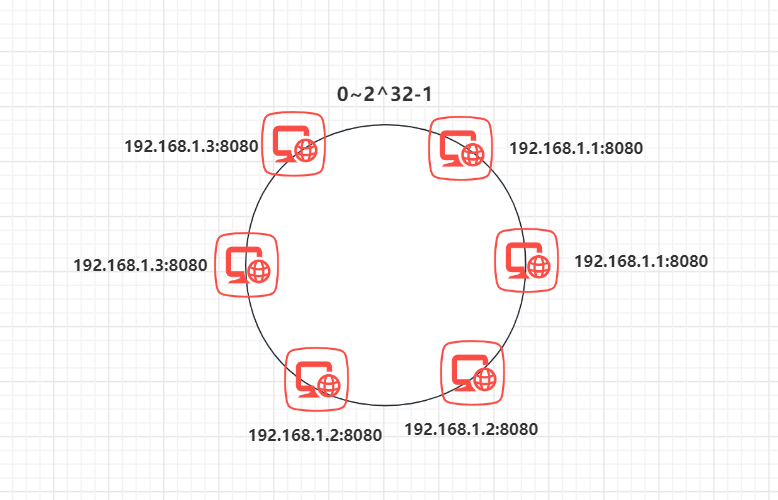
到目前为止该算法依然也有点问题: 当节点较少时会出现数据分布不均匀的情况:
这样会导致大部分数据都在 N1 节点,只有少量的数据在 N2 节点。
为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点:
计算时可以在 IP 后加上编号来生成哈希值。
这样只需要在原有的基础上多一步由虚拟节点映射到实际节点的步骤即可让少量节点也能满足均匀性。
总结一下一致性 Hash 算法的一些特点:
- 构造一个
0 ~ 2^32-1大小的环。 - 服务节点经过 hash 之后将自身存放到环中的下标中。
- 客户端根据自身的某些数据 hash 之后也定位到这个环中。
- 通过顺时针找到离他最近的一个节点,也就是这次路由的服务节点。
- 考虑到服务节点的个数以及 hash 算法的问题导致环中的数据分布不均匀时引入了虚拟节点。
实战应用
这里的算法参考自 xxl-job,网上也有其他不同的实现,比如 FNV1_32_HASH 等,实现不同但是目的都一样;代码里包括了上文提到的虚拟节点以及 hash 算法。
注意这里使用了 TreeMap 的一些 API:
- 写入数据候,
TreeMap可以保证 key 的自然排序。 tailMap可以获取比当前 key 大的部分数据。- 当这个方法有数据返回时取第一个就是顺时针中的第一个节点了。
- 如果没有返回那就直接取整个
Map的第一个节点,同样也实现了环形结构。
常见问题
- 为什么要使用一致性 hash
保证每个任务固定调度其中一台机器,避免资源的重复申请。
2.怎么变成环的
如果顺时针找不到就取第一个
- 为什么用 TreeMap
TreeMap 既能做到有序又能实现快速查找
- 为什么使用了 hash 和 md5
为了散列均匀

